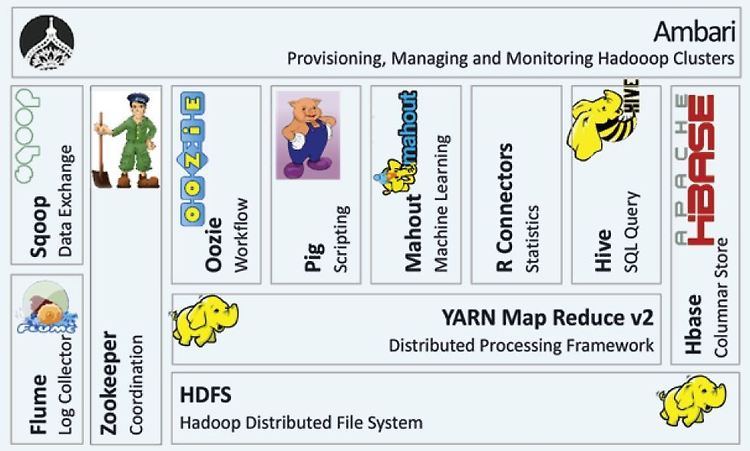
하둡 에코 시스템(Hadoop Eco System) 에 대해서
2023. 2. 5. 17:07
데이터 엔지니어링/Hadoop
하둡 에코 시스템에 대해서 공부한 내용을 정리해보려고 한다. 하둡 에코 시스템(Hadoop Eco System) 이란 기본적으로 하둡은 HDFS 와 MapReduce, YARN 으로 구성되어있다. 하지만 그 외의 다양한 서브 프로젝트들이 많이 있다. 하둡 에코 시스템은 이러한 서브 프로젝트들의 모임이라고 생각하면 된다. 하둡 에코 시스템에 대한 설명으로 가장 많이 보이는 사진이 있다. 사진을 보면 다음과 같은 에코 시스템이 있는 것을 확인할 수 있었다. 위의 사진에 나오는 사진에서 보이는 여러 서브 프로젝트들이 무엇이고 어떻게 사용되는지에 대해서 정리해보려고 한다. Flume 대용량의 로그를 수집할 수 있도록 여러가지 기능을 제공하는 프로그램이다. Flume 말고도 chukwa, scribe, fleun..
HDFS(Hadoop Distributed File System) 이해하기
2023. 2. 5. 15:26
데이터 엔지니어링/Hadoop
HDFS 에 대해서 찾아보며 공부한 내용을 정리해보려고 한다. HDFS(Hadoop Distributed File System) 옛날에는 한 대의 컴퓨터에 많은 데이터를 저장했고 큰 작업들을 수행했다. 하지만 데이터의 양이 점점 많아지면서 한 대의 컴퓨터에서 처리하기에는 필요한 비용이 기하급수적으로 늘었다고 한다. 그래서 구글에서 저사양의 컴퓨터를 여러 대 모아 한대의 컴퓨터처럼 동작하는 모델을 설계했고 바로 그 모델이 GFS(Google File System) 이라고 한다. HDFS 는 GFS 의 모델을 바탕으로 설계되었다고 한다. HDFS 의 특징으로 저장된 파일은 데이터 무결성으로 수정이 불가능하다. HDFS 는 한번 쓰고 여러번 읽는 목적에서 설계되었다고 한다. 읽기 중심의 파일시스템이라고 생각할..
하둡(Hadoop) 에 대해서
2023. 2. 5. 15:10
데이터 엔지니어링/Hadoop
하둡(Hadoop) 이란? 하둡 에코 시스템에 대해서 이해하기 전에 하둡이 뭔지부터 알아야 한다. 하둡은 "대량의 데이터를 분산 처리하고 저장하기 위한 플랫폼" 이라고 말한다. 하둡 아래와 같이 분산 파일 시스템이라고 하는 HDFS(Hadoop Distributed File System) 과 분산 데이터 처리를 해주는 MapReduce(MR) 으로 구성되어있다. 추가로 하둡 2.0 버전부터는 YARN(Yet Another Resource Negotiator) 이라는 것을 통해 자원을 관리한다고 한다. 여기서 나오는 3 가지 요소를 시작으로 하둡에 대해서 이해하면 좋을 것 같다. HDFS(Hadoop Distributed File System) MapReduce(MR) YARN(Yet Another Res..
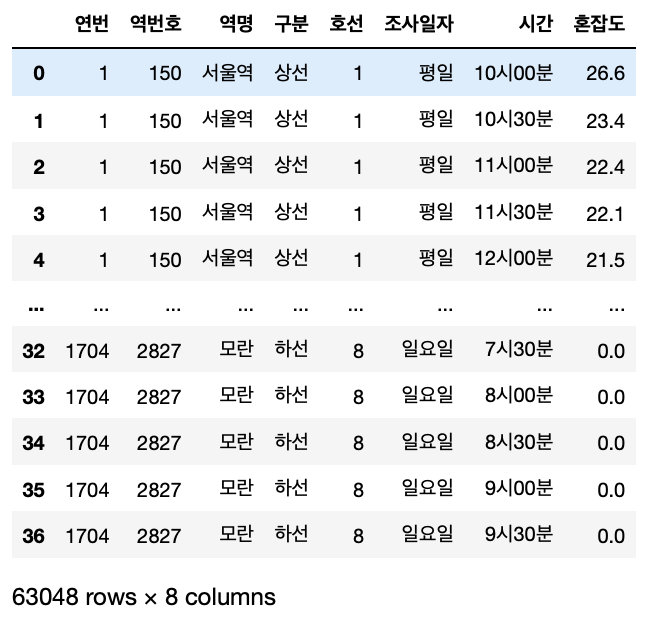
3. 공공데이터포털 데이터 전처리하기(2)
2023. 1. 2. 19:08
데이터 엔지니어링/Airflow
개요 지난 번에 1704 건의 데이터를 전처리하기 앞서 1 건의 데이터를 가져와 내가 원하는 데이터로 변환하는 부분까지 해봤다. 여러 삽질 끝에 원하는 데이터를 만들 수 있었고 1 건의 데이터만 가져와서 테스트해봤기 때문에 이번에는 모든 데이터를 전처리해서 내가 원하는 데이터로 만들어봤다. 모든 데이터 전처리하기 나는 1704개의 데이터를 일괄 처리하기 힘들 것 같다고 생각이 들었고 한 건의 데이터마다 전처리 후에 추가해주면 되지 않을까 하는 생각이 들었다. 그래서 1건의 데이터를 가져와 전처리하고 추가해주는 소스를 작성하고 결과를 확인해봤다. 우선 기본적으로 이전에 적었던 내용을 기본으로 전처리를 진행했다. 크게 틀은 벗어나지 않았던 것 같다. 2. 공공데이터포털 데이터 전처리하기(1) 개요 공공데이터..

2. 공공데이터포털 데이터 전처리하기 (1)
2022. 12. 31. 20:47
데이터 엔지니어링/Airflow
개요 공공데이터포털에서 데이터를 json 타입으로 가져오는 것까지 해봤고 데이터를 가져오는 과정을 Airflow DAG 로 만들어 작업을 수행해 원하는 디렉토리에 저장하는 과정까지 해봤다. 이번에는 그렇게 가져온 json 타입의 데이터를 가져와 원하는 데이터로 만드는 과정을 진행해보려고 한다. 그렇게 원하는 데이터가 만들어지면 Mysql 에 테이블을 생성하고 테이블에 저장하는 과정까지 생각하고 있다. 그래서 나는 Pandas 를 사용해 전처리를 진행하려고 하고 이러한 과정을 jupyter Notebook 에서 사용해보려고 한다. 해보기 앞서, 나는 다음과 같이 데이터를 만들어보고 싶다. 아래와 같이 컬럼명으로 되어있는 시간을 값으로 넣고 그 시간에 대한 혼잡도를 같이 넣고 싶었다. 하고나서는 쉬울줄 알았..

1. 공공데이터포털 데이터 가져오기
2022. 12. 25. 23:37
데이터 엔지니어링/Airflow
공공데이터포털 데이터 가져오기 내가 사용하기로한 공공데이터포털의 데이터("서울교통공사_지하철혼잡도정보")를 가져오기 위해서 제공하는 API 를 통해 데이터를 가져올 수 있다. 포털에서 API 를 생성할 수 있도록 제공해주는 기능이 있는데 인증키를 등록하고 API 를 호출할 수 있는 URL 을 생성해준다. 그래서 다음과 같이 URL 을 실행하면 다음과 같이 데이터를 확인할 수 있다. curl -X GET "https://api.odcloud.kr/api/15071311/v1/uddi:b3803d43-ffe3-4d17-9024-fd6cfa37c284?page=1&perPage=10&serviceKey=[서비스키]" -H "accept: application/json" -H "Authorization: [인증..
0. Airflow 데이터 파이프라인 만들어보기 (토이 프로젝트)
2022. 12. 25. 22:50
데이터 엔지니어링/Airflow
개요 개인적으로 공부할겸 Airflow 를 사용해서 데이터 파이프라인을 만들어보려고 한다. 어떤 데이터를 사용해볼까 생각하다 공공데이터포털 이란 곳에서 공공데이터를 제공해주고 있어 사용해보기로 했다. https://www.data.go.kr 공공데이터 포털 국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase www.data.go.kr 공공데이터포털에서는 다양한 데이터 타입으로 데이터를 제공하고 있어 어떤 데이터를 다루어볼지 그리고 어떤 형식으로 데이터를 가져올지 등에 대해서 생각해봐야했다. 나는 수많은 데이터 중에서 서울교통공사_지하철혼잡도정보 라는 데이터를 가져..
Mysql CASE 문법 사용법
2022. 12. 5. 18:19
데이터 엔지니어링/Database
Mysql 에서 출력할 때 조건을 통해 값을 반환하기 위해서 CASE 문법을 사용한다. CASE 문법의 사용법에 대해서 정리해봤다. CASE 문법의 사용법은 다음과 같다. CASE WHEN [조건1] THEN [반환값1] WHEN [조건2] THEN [반환값2] WHEN [조건n] THEN [반환값n] ELSE [반환값] END CASE 문법은 다음과 같이 사용할 수 있다. WHEN ~ THEN 은 항상 같이 사용해야 한다. WHEN ~ THEN 은 여러개 사용할 수 있다. WHEN ~ THEN 조건에 충족되지 않을 경우 ELSE 의 값이 반환된다. 만약 ELSE 가 없다면 NULL 을 반환한다. 예를 들어, 다음과 같이 사용해볼 수 있다. SELECT CASE WHEN score >= 90 THEN '..