
Spark explode() 사용해서 List 로 된 컬럼을 행으로 분리하기
2023. 10. 1. 17:57
데이터 엔지니어링/Spark
Spark Dataframe 에 다음과 같이 리스트 형태로 들어간 컬럼이 있을 것이다. scala> val df = Seq(("Nam", List("A", "B", "C", "D"))).toDF("name", "grade") df: org.apache.spark.sql.DataFrame = [name: string, grade: array] scala> df.show() +----+------------+ |name| grade| +----+------------+ | Nam|[A, B, C, D]| +----+------------+ 이런 경우에 grade 라는 컬럼을 각 row 로 분리할 필요가 생길수도 있다. 이때, explode() 함수를 통해서 리스트를 각 row 로 분리해줄 수 있다. 원하는 ..

Spark User Defined Functions (UDFs)
2023. 10. 1. 17:29
데이터 엔지니어링/Spark
Spark 를 사용하다보면 UDFs 를 사용하여 새로운 column 을 만드는 경우가 많이 있다. 그래서 Spark UDFs 에 대해서 정확하게 무엇을 말하고 어떻게 사용하는 지에 대해서 정리해보려고 한다. 정리는 아래의 공식 문서를 참고해서 정리해보았다. https://spark.apache.org/docs/latest/sql-ref-functions-udf-scalar.html Scalar User Defined Functions (UDFs) - Spark 3.5.0 Documentation spark.apache.org Spark User-Defined Functions Spark User-Defined Functions (UDFs) 는 하나의 행에서 동작하는 사용자가 프로그래밍할 수 있는 루틴을 ..
Spark multi process error in macOS
2023. 9. 27. 11:26
데이터 엔지니어링/Spark
macos 에서 pyspark 를 통해 디버깅을 하던 도중 다음과 같은 에러가 발생했다. To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/09/27 10:36:44 WARN package: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.sql.debug.maxToStringFields'. objc[7304]: +[__NSCFConstantString initialize] may have been in progress in..
Spark JDBC Data Source Option
2023. 9. 26. 12:32
데이터 엔지니어링/Spark
spark 를 통해 JDBC 를 통해 데이터베이스의 테이블을 불러올 때 사용하는 옵션에 대해서 정리해보려고 한다. Spark JDBC To Other Databases 해당 내용은 야래의 spark 공식 문서에서 확인할 수 있다. https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html JDBC To Other Databases - Spark 3.5.0 Documentation spark.apache.org 문서를 보면 다음과 같이 설명이 되어있다. Spark SQL 은 JDBC 를 사용해서 다른 데이터베이스들로부터 데이터를 읽을 수 있는 data source 를 포함하고 있다. 이 기능은 JdbcRDD 를 사용하는 것보다 선호된다. 그 이유는 D..
spark config 리스트 정리 (spark.config.set)
2023. 9. 17. 19:44
데이터 엔지니어링/Spark
spark config 에 대해서 정리하려고 한다. 사용해본 config 설정이 많지는 않지만 여러 config 들에 대해서 계속해서 정리해나가야겠다. spark config setting 방법 # spark session 생성 spark = SparkSession.builder.appName("test").getOrCreate() # config 예시 spark.conf.set("spark.sql.inMemoryColumnarStorage.compressed", True) spark.conf.set("spark.sql.adaptive.enabled", True) spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", True) spark.co..
페이로드(Payload) 에 대해서
2023. 8. 13. 18:26
데이터 엔지니어링/개념정리
내가 알고 있는 페이로드는 데이터를 요청했을 때 응답으로 보내지는 데이터 부분이라고 알고 있다. 그래서 정확히 페이로드가 무엇인지에 대해서 정리해보려고 한다. 페이로드(Payload) 란 페이로드(Payload) 는 전송되는 데이터 를 의미한다. 페이로드 는 전송의 근본적인 목적이 되는 데이터의 일부분으로 그 데이터와 함께 전송되는 헤더와 메타데이터와 같은 부분을 제외한 데이터이다. 컴퓨터 보안에서는 페이로드를 멀웨어의 일부를 뜻한다. 페이로드(Payload) 라는 용어는 큰 데이터 덩어리 중 '흥미 있는' 데이터를 구별하는 데 사용한다. 또한 운송업에서 비롯된 용어인데 지급(pay) 해야하는 적화물(load) 를 의미한다고 한다. 프로그래밍에서는 주로 메시지 프로토콜 중에서 프로토콜 오버헤드와 원하는 ..
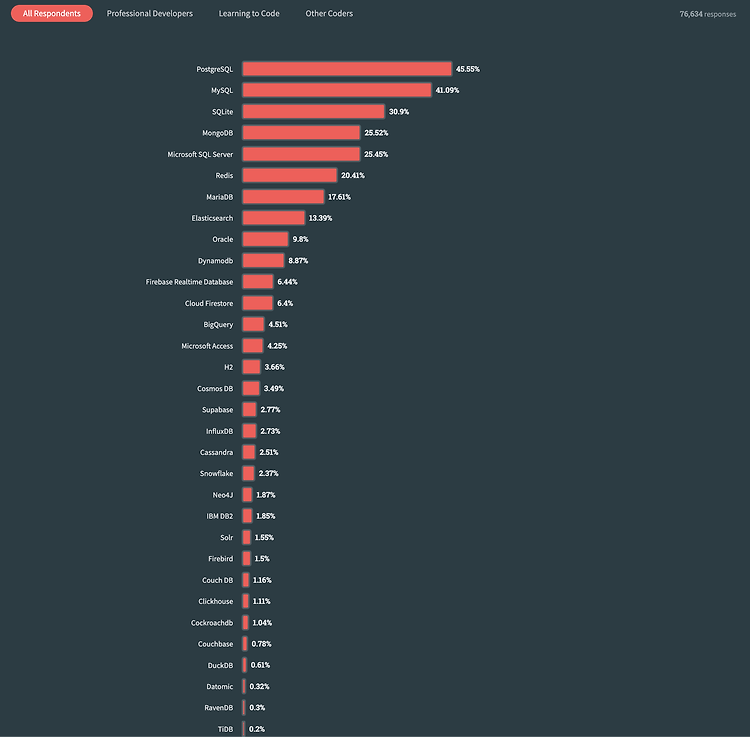
Postgresql 과 MySQL 비교
2023. 8. 10. 21:46
데이터 엔지니어링/Database
stackoverflow developer Survey 2023 에서 개발자들 사용하는 데이터베이스에 대해서 투표한 결과를 보게 되었다. https://survey.stackoverflow.co/2023/ Stack Overflow Developer Survey 2023 In May 2023 over 90,000 developers responded to our annual survey about how they learn and level up, which tools they're using, and which ones they want. survey.stackoverflow.co 투표 결과를 확인해보니 대략 7만 5천명의 개발자분들이 투표해주셨고 그 결과는 다음과 같았다. 전체 결과를 확인해보니 Po..
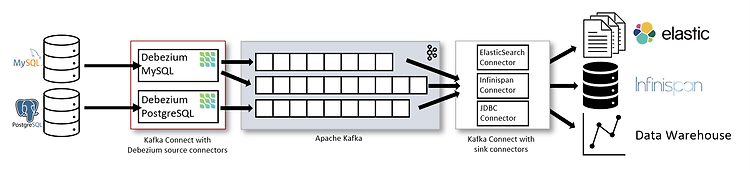
Debezium 에 대해서
2023. 7. 31. 18:06
데이터 엔지니어링/개념정리
향후 일을 하기 전에 어떤 기술 스텍들을 사용하는지 알아보던 중 Debezium 이라는 기술을 처음 들어보게 되었다. 그래서 Debezium 이 뭔지 알아보려고 한다. Debezium 이란? Debezium (이하, 데베지움) 의 공식 문서는 아래의 사이트에서 확인할 수 있다. https://debezium.io/ Debezium Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps com..