
개요
공공데이터포털에서 데이터를 json 타입으로 가져오는 것까지 해봤고
데이터를 가져오는 과정을 Airflow DAG 로 만들어 작업을 수행해 원하는 디렉토리에 저장하는 과정까지 해봤다.
이번에는 그렇게 가져온 json 타입의 데이터를 가져와 원하는 데이터로 만드는 과정을 진행해보려고 한다.
그렇게 원하는 데이터가 만들어지면 Mysql 에 테이블을 생성하고 테이블에 저장하는 과정까지 생각하고 있다.
그래서 나는 Pandas 를 사용해 전처리를 진행하려고 하고 이러한 과정을 jupyter Notebook 에서 사용해보려고 한다.
해보기 앞서, 나는 다음과 같이 데이터를 만들어보고 싶다.
아래와 같이 컬럼명으로 되어있는 시간을 값으로 넣고 그 시간에 대한 혼잡도를 같이 넣고 싶었다.
하고나서는 쉬울줄 알았는데 생각보다 많은 삽질을 했었던 것 같다. 거의 이 방법, 저 방법 다해봤었는데
쉬운 방법이 있다는 걸 뒤늦게 알았다,, ㅎㅎㅎ
<전처리 전 데이터>
<전처리 후 데이터>

내가 어떻게 데이터를 가져올 수 있었는지에 대해서 하나씩 정리해봤다.
Json 타입의 데이터 가져오기
우선 파이썬을 사용해 json 타입의 데이터를 가져와야 한다.
다음과 같이 데이터를 가져올 수 있었다.
import json
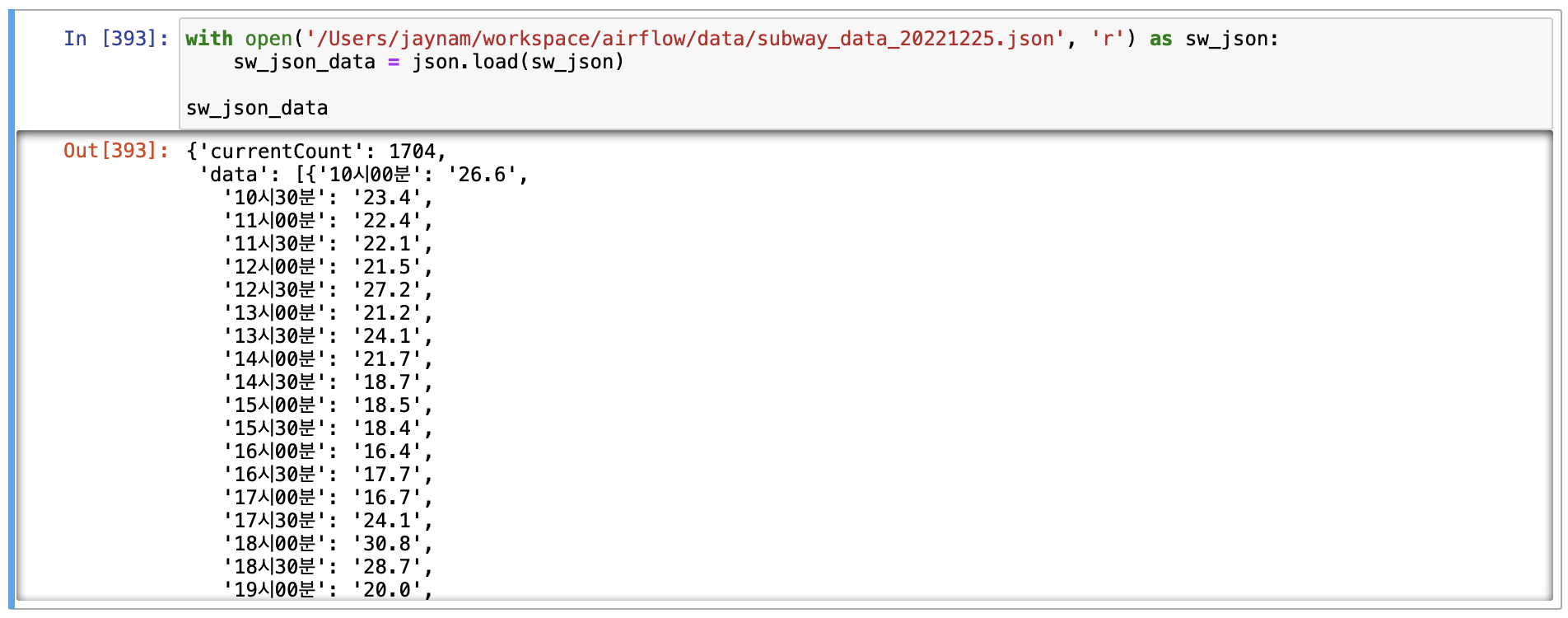
with open('/Users/jaynam/workspace/airflow/data/subway_data_20221225.json', 'r') as sw_json:
sw_json_data = json.load(sw_json)
sw_json_data
Python json 라이브러리를 가져와 사용했고 로컬의 절대경로를 통해 json 파일을 가져왔다.
그리고 파일을 가져와 json 형식으로 불러와 값을 저장해주었다.
결과를 확인해보면 아래처럼 한줄로 나오는 것이 아니라 json 타입에 맞게 값이 나오는 것을 확인할 수 있었다.
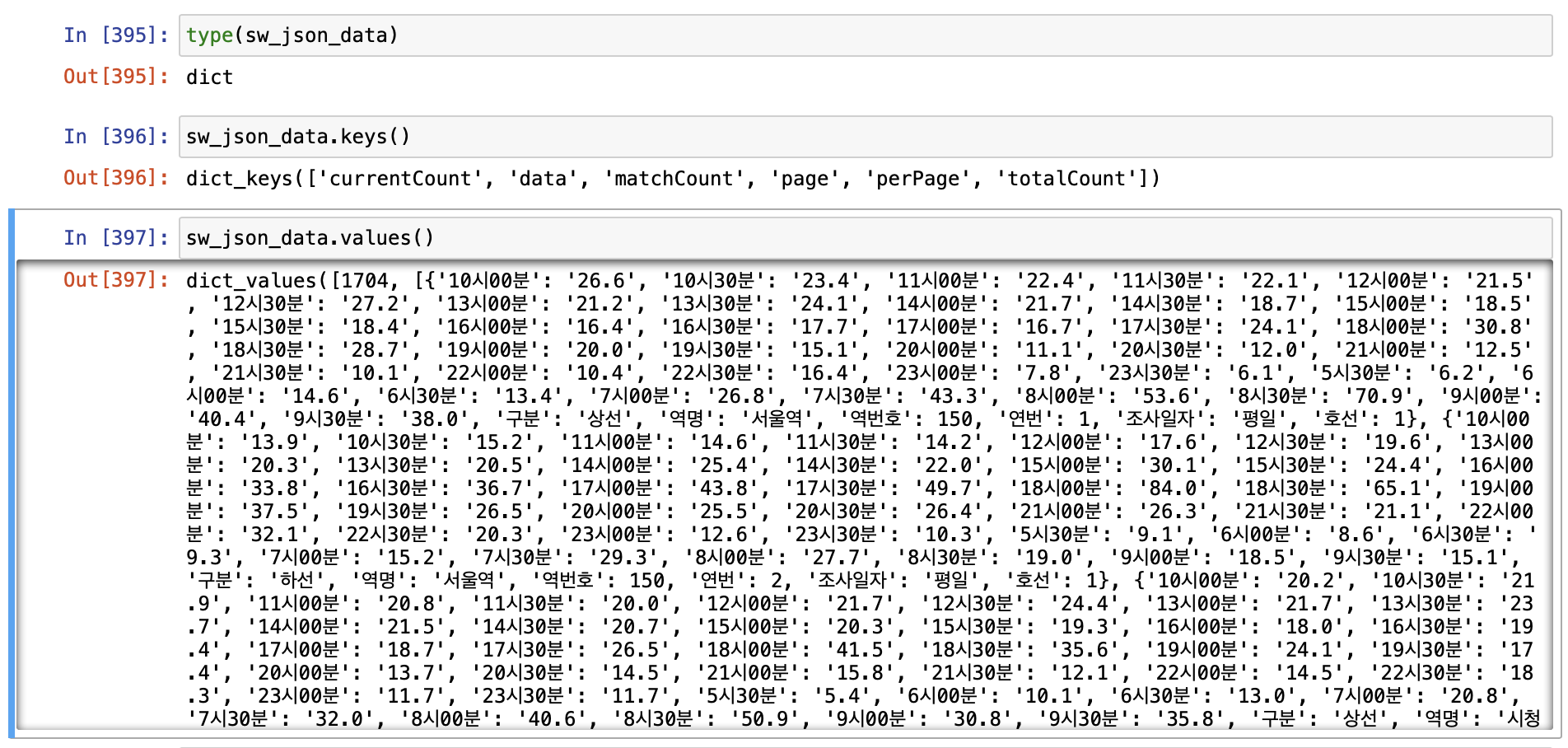
그리고 추가로 Type 과 key, value 값도 확인해봤다.
# type 확인
type(sw_json_data)
# key 확인
sw_json_data.keys()
# value 확인
sw_json_data.values()
type 은 딕셔너리 타입으로 되어있고 key 와 value 값을 확인할 수 있었다.
많은 값 중에서 'data' 라는 key 값을 가진 값들만 필요했기 때문에 다음과 같이 필요한 데이터만 가져왔다.
sw_json_data['data']이렇게 key 값으로 지정된 값을 가져올 수 있다.

'data' 라는 key 값에 들어있는 value 의 개수는 1704개가 들어있었다. 즉, row 의 수가 1704개가 된다는 것이다.
len(sw_json_data['data'])
그 중에서 나는 하나의 value 만 가져와 테스트를 진행하려고 생각했기 때문에
많은 value 중에서 특정 값을 가져오기 위해서는 아래와 같이 가져올 수 있었다.
sw_json_data['data'][0]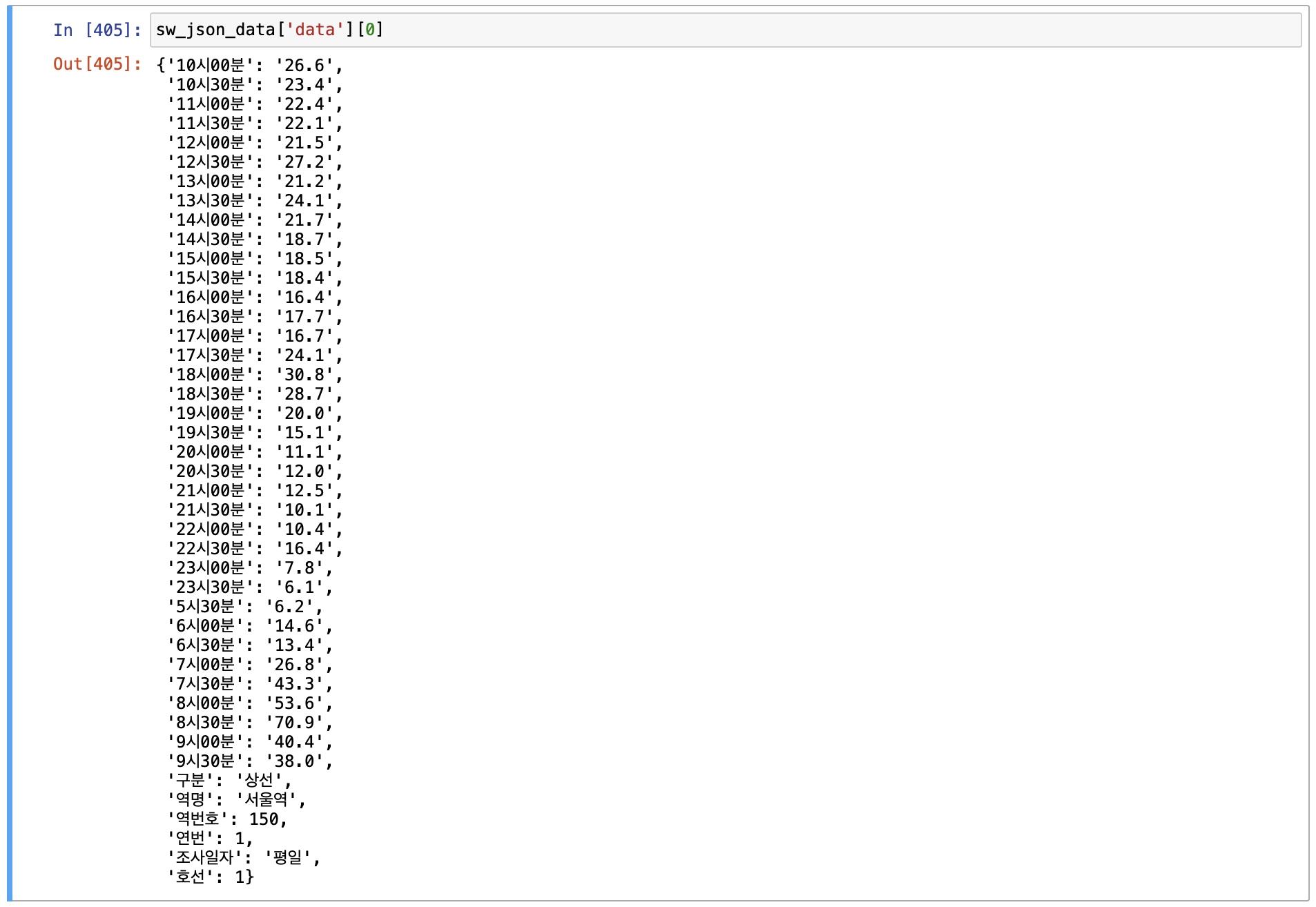
여기까지 json 타입의 데이터를 가져와 테스트를 하기 위한 준비는 다 되었다.
이제 이 값을 가지고 원하는 데이터로 만들면 된다!
Json 타입을 Dataframe 타입으로 변환하기
json 타입의 데이터를 Pandas 를 사용해서 Dataframe 타입으로 변환해보려고 한다.
나는 pandas 의 json_normalize() 함수를 통해 Dataframe 타입으로 만들어봤다.
import pandas as pd
sw_df = pd.json_normalize(sw_json_data['data'][0])
sw_df
json_normalize() 함수에 대해서도 시간이 된다면 어떻게 사용되고 동작하는지에 대해서도 간단하게나마 정리해두어야 겠다.
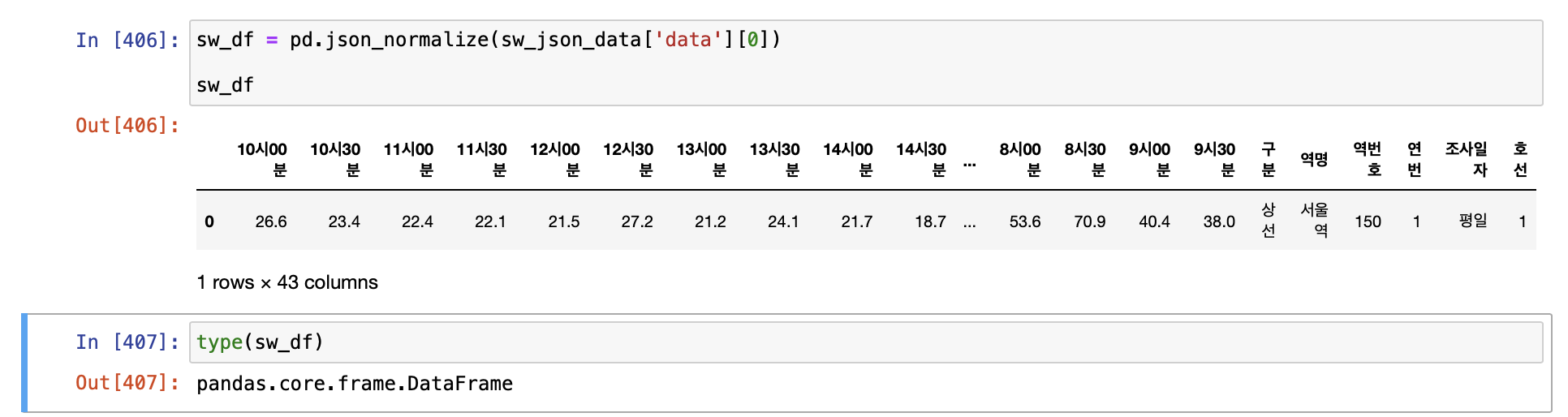
실행 결과와 같이 보다 보기 쉽게 Dataframe 타입으로 생성된 것을 확인할 수 있었다.
원하는 데이터 만들어보기
이제는 위에서 만든 데이터를 어떻게 쪼개서 원하는 데이터로 만들지 고민을 많이 했다.
시간 부분과 아닌 부분을 쪼개야 하고 다시 Join 해서 데이터를 만드는 과정이 필요했다.
Dataframe 나누기
먼저 시간 부분과 아닌 부분을 나누어야 했다. 나는 다음과 같이 나누어봤다.
sub_list = ['연번', '역번호', '역명', '구분', '호선', '조사일자']
time_list = ['10시00분', '10시30분',
'11시00분', '11시30분',
'12시00분', '12시30분',
'13시00분', '13시30분',
'14시00분', '14시30분',
'15시00분', '15시30분',
'16시00분', '16시30분',
'17시00분', '17시30분',
'18시00분', '18시30분',
'19시00분', '19시30분',
'20시00분', '20시30분',
'21시00분', '21시30분',
'22시00분', '22시30분',
'23시00분', '23시30분',
'5시30분',
'6시00분', '6시30분',
'7시00분', '7시30분',
'8시00분', '8시30분',
'9시00분', '9시30분' ]
info_df = sw_df[sub_list]
time_df = sw_df[time_list]
역시 단순한게 빠를 때가 있다는 사실을 잊지 말아야 한다. 처음에는 시간을 뽑아서 가져오고 그 시간에 맞는 데이터를 넣어주고 무언가 코드를 만들어야겠다는 생각을 많이 했었는데 오히려 단순하게 컬럼을 그대로 리스트로 만들어서 그 리스트에 있는 데이터만 가져오다보니 약간의 작업으로 훨씬 편하고 쉽게 가져올 수 있었던 것 같다.
이렇게 가져온 결과는 다음과 같았다.
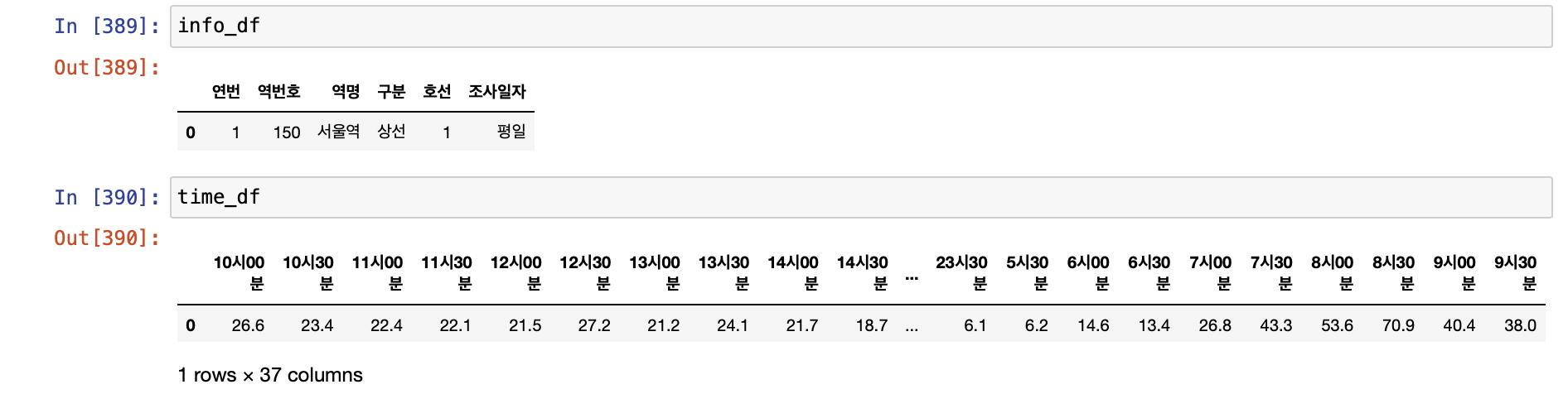
자, 그럼 이제 이 데이터를 아래와 같이 만들어주어야 한다!
그러기 위해서는 시간 Dataframe 을 행열을 바꾸어 주어야 했다.
행열은 transpose() 함수를 통해 바꾸어줄 수 있다.
time_df.transpose()
그럼 역에 대한 정보를 가진 Dataframe 을 확인해보면 다음과 같고

이 역 정보를 가진 Dataframe 과 join 을 하기 위해서는 인덱스를 설정해주어야 했다.
그래서 다음과 같이 인덱스와 필요한 컬럼을 추가해주었다.
# 행열 바꾸기
time_rev = time_df.transpose()
# 컬럼 추가
time_rev.rename(columns = {0 : '혼잡도'}, inplace = True)
time_rev['시간'] = time_df.columns.values
time_rev['연번'] = info_df['연번'][0]
# 컬럼 순서 변경
time_rfm = time_rev[['연번', '시간', '혼잡도']]
# 인덱스 설정
time_res = time_rfm.set_index('연번')
time_res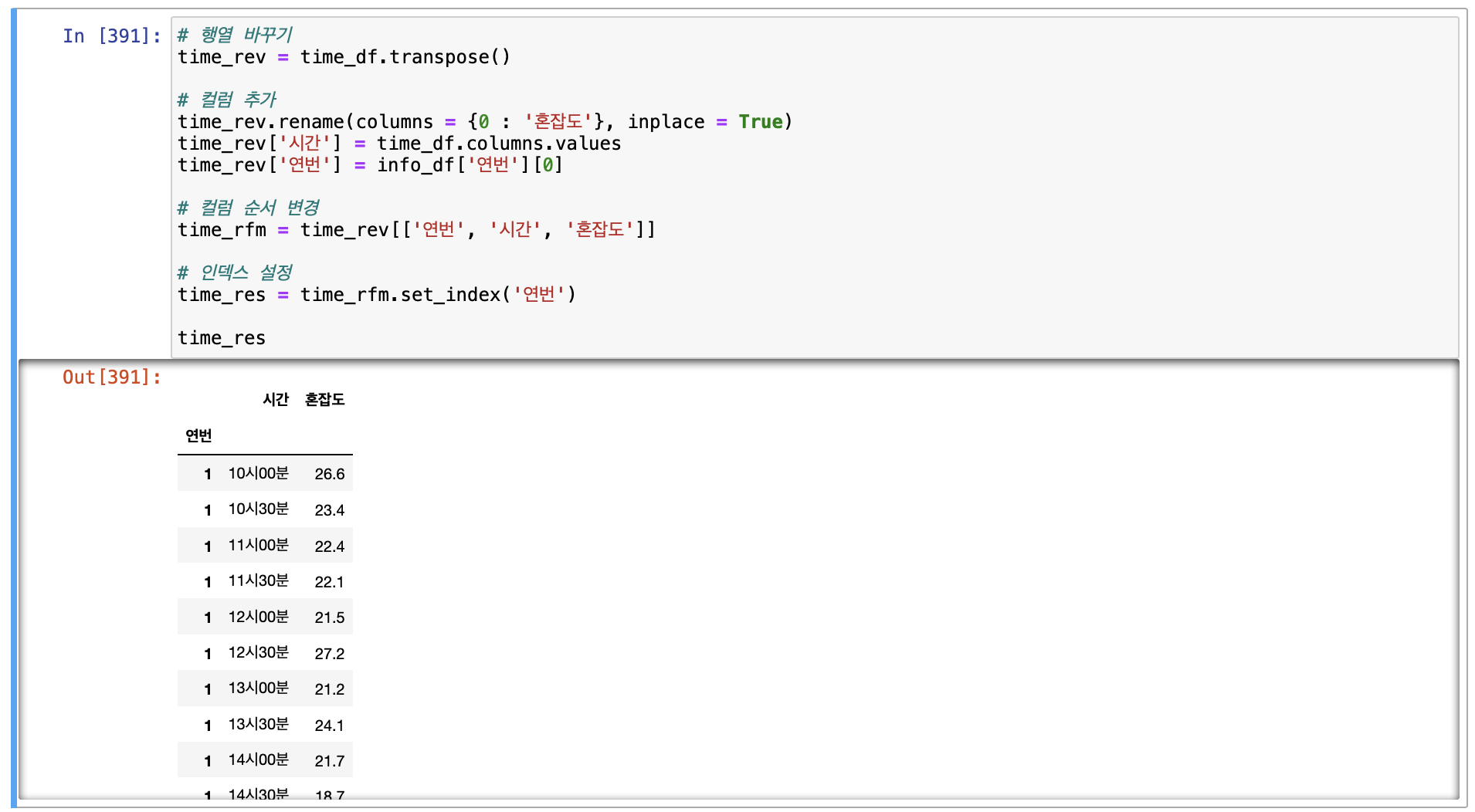
결과를 보면 '연번' 이라는 인덱스가 추가되었고 그리고 '시간' 이라는 컬럼을 추가하고
'혼잡도' 라고 기존의 0으로 되어있던 컬럼명을 바꾸어주었다.
이제 아래의 2개의 Dataframe 을 join 해주었다.
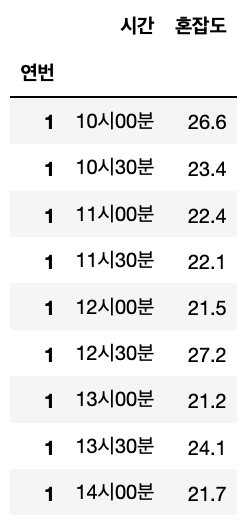
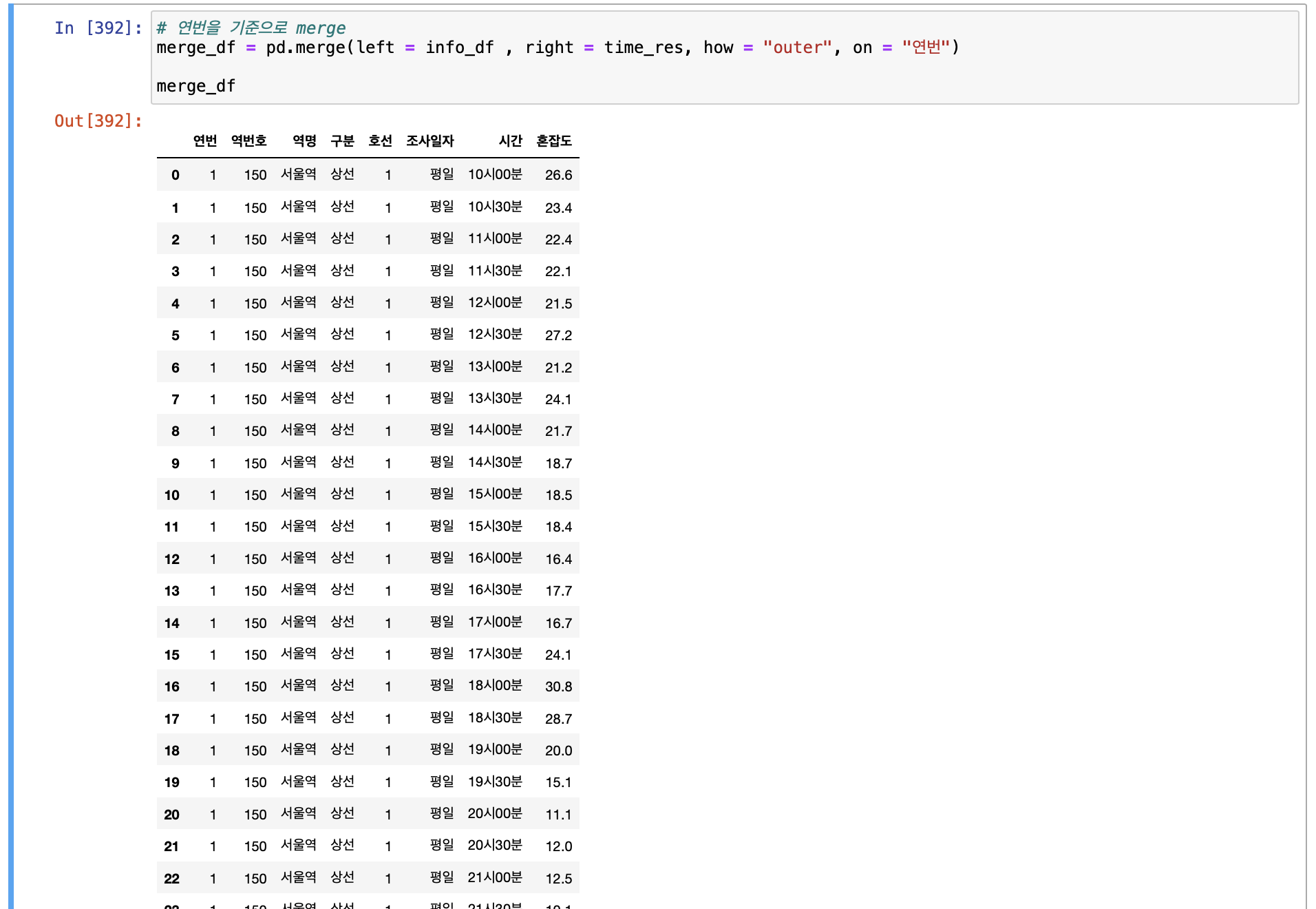
나는 pandas 의 merge() 함수를 사용해서 '연번' 을 조건으로 outer join 을 해주었다.
# 연번을 기준으로 merge
merge_df = pd.merge(left = info_df , right = time_res, how = "outer", on = "연번")
merge_df
이렇게 내가 원하는 데이터를 만들 수 있었다.
마무리
사실 처음에 내가 생각한 데이터를 만들기 위해서 어떻게 해야할지 고민을 많이했었다.
아무런 생각없이 쪼개서 2개의 DataFrame 으로 만들어 한쪽으로 합쳐주면되는건가.. 생각했었다.
아니면 리스트로 만들어서 다시 DataFrame 으로 만드는건가... 이 생각, 저 생각 많이 했었던 것 같다.
결국에는 join 을 하면 쉽게 데이터를 만들 수 있다는 생각이 들었고 join 을 하기 위해서는 각 Dataframe 에 index 를 생성해주어야 한다는 걸 알았고 그렇게 index 를 추가해서 join 했고 원하는 데이터를 얻을 수 있게 되었다.
그리고 이런 과정을 해보면서 많은 고민을 했었던 것 같다.
어떻게 데이터를 가져와야 효율적으로 사용할 수 있을까?
내가 원하는 데이터를 가져왔을 때 그 이후에 사용했을 때의 문제는 없을까?
굳이 데이터를 변경해서 가져와야하는 이유가 있을까?
있는 그대로의 데이터만 가져와도 보다 무리는 없지 않을까?
와 같이 어떻게 데이터를 만들어야 효율적으로 사용할 수 있을것인가에 대한 고민들이 많았던 것 같다.ㅎㅎ
사실 아직도 어떻게 해야할지 잘 모르겠다. 계속 이것저것 해보는 수 밖에!
마지막으로 jupyter Notebook 의 실행 횟수를 보면 알 수 있듯이 열심히 찾아보고 시도해보고 그 끝에 원하는 결과가 나오니까 나름 뿌듯하다 ㅎㅎ 이제 하나 해봤으니까 전체 데이터를 해봐야겠다. 이제 시작이지!!!
'데이터 엔지니어링 > Airflow' 카테고리의 다른 글
| airflow Dynamic Task Mapping (0) | 2023.12.28 |
|---|---|
| 3. 공공데이터포털 데이터 전처리하기(2) (0) | 2023.01.02 |
| 1. 공공데이터포털 데이터 가져오기 (0) | 2022.12.25 |
| 0. Airflow 데이터 파이프라인 만들어보기 (토이 프로젝트) (0) | 2022.12.25 |
| [Error] airflow.exceptions.AirflowException: The webserver is already running under PID (0) | 2022.11.18 |