4주차 심화 과정에 대해서 내가 작성한 코드를 정리해보았다.
📌 문제 1
우선 문제를 풀기 위해서 애너그램 대해서 이해해야 했다.
애너그램이란 문자를 재배열하여 다른 뜻을 가진 단어로 바꾸는 것을 말하는데
예를 정말 잘 들어주셔서 쉽게 이해할 수 있었다.
예를 들어, 영어의 'tea'와 'eat'와 같이 각 단어를 구성하는 알파벳은 같은데 뜻이 다른 두 단어
그리고 우리말에서 '문전박대' 와 '대박전문' 과 같이 같은 네 글자를 사용하지만 순서를 바꾸어 다른 뜻으로 사용할 수 있는 것을 애너그램이라고 한다.
문제를 풀기 위해서 강의를 통해 배운 알고리즘을 사용해야 했고
함수를 효율적으로 사용하고 싶어 함수를 사용하는 부분에 더 많은 고민을 했던 것 같다.
그리고 코딩 컨벤션을 통해 코드 스타일을 적용해 보았고 코드 하나하나 열심히 주석을 달아서 설명을 해봤다.
하지만 주석을 통해 설명을 적으면서 많은 주석이 오히려 가독성을 떨어뜨릴 수 있다는 생각이 들었다.
어떻게 하면 효율적으로 주석을 달 수 있을 지 그리고 최소한의 주석으로 코드를 잘 설명할 수 있을지에 대해서도 생각해봐야겠다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <cs50.h>
// 함수 선언하기
void print_anagram(const char* s1, const char* s2); // 결과를 출력해주는 함수
int is_anagram(const char* s1, const char* s2); // 애나그램인지 구별해주는 함수
char* selection_sort(const char* s); // 선택 정렬 함수
int main(int argc, char *argv[]) {
// 숫자를 입력받는 부분은 따로 구현하지 않고 배열로 선언한다.
char* input1[2] = {"12345", "54321"};
char* input2[2] = {"14258", "25431"};
char* input3[2] = {"11132", "21131"};
// 결과 출력
print_anagram(input1[0], input1[1]);
print_anagram(input2[0], input2[1]);
print_anagram(input3[0], input3[1]);
return 0;
}
// 애나그램인지 아닌지 확인 후 출력해주는 함수
void print_anagram(const char* s1, const char* s2) {
printf("입력값: %s, %s", s1, s2);
// is_anagram() 함수는 int 타입이고, 0 또는 1을 반환한다.
if(is_anagram(s1, s2)) { // is_anagram() 함수가 1을 반환하면 True
printf(" => 출력값: True\n");
} else { // is_anagram() 함수가 0을 반환하면 False
printf(" => 출력값: False\n");
}
}
// 두 문자열이 애나그램인지 확인해주는 함수
int is_anagram(const char* s1, const char* s2) {
// 두 문자열의 길이 비교
if(strlen(s1) != strlen(s2)) {
printf("두 숫자의 길이가 다릅니다. \n");
return 0;
}
// 선택 정렬을 통해 정렬된 문자열 저장
char* sorted_s1 = selection_sort(s1);
char* sorted_s2 = selection_sort(s2);
// strcmp() 함수로 정렬된 두 문자열을 비교해서 같은지 확인
if (strcmp(sorted_s1, sorted_s2) == 0) {
// if() 조건문 안에서 1 이면 True 를 의미하기 때문에 같으면 1 을 반환
return 1;
} else {
// if() 조건문 안에서 0 이면 False 를 의미하기 때문에 같으면 0 을 반환
return 0;
}
}
// 선택 정렬을 해주는 함수
char* selection_sort(const char* s) {
// 변수 선언
int index;
char temp, min;
// malloc 함수를 사용해 메모리 공간을 할당 받았다.
// 참고 : https://blockdmask.tistory.com/56
char *str = malloc(sizeof(char) * strlen(s));
// strcpy() 함수를 통해 입력받은 문자열 s 를 str 로 복사해서 사용했다.
// malloc 함수로 할당받은 메모리 공간에 문자열을 입력(복사)해준다.
strcpy(str, s);
for(int i=0; i<5; i++) {
// 현재 위치(i)와 현재 값(min = str[i])을 초기값으로 설정
index = i;
min = str[i];
for (int j=i+1; j<5; j++) {
// 값을 비교해 최솟값(min = str[j])를 갱신해주고 그 위치(index = j)를 기억한다.
if (min > str[j] ) {
min = str[j]; // 최솟값을 저장
index = j; // 최솟값 위치를 저장
}
}
// 모든 배열을 비교해 최솟값을 찾고나면
// 최솟값(min 의 위치(index)를 현재 위치(i)의 값과 바꾼다.
if (i != index) { // 현재 위치와 다르다면
temp = str[i]; // 비어있는 문자 temp 에 str[i] 를 넣어준다. temp <- str[i]
str[i] = str[index]; // str[i] 에 str[index] 의 값을 저장해준다. str[i] <- str[index]
str[index] = temp; // str[index] 에 temp (str[i]) 의 값을 저장해준다. str[index] <- temp
}
}
// 정렬된 배열 반환
return str;
}
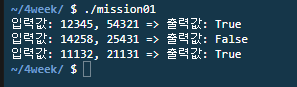
[실행 결과]
[피드백]
함수내에서 변수를 선언하게 되면 메모리 공간의 stack에 할당되고,
함수 종료시 스택이 알아서 비워지지만 함수내에서 동적할당(malloc)을 사용하는 경우는 다릅니다.
malloc은 메모리 heap공간에 할당되며, 함수 종료시에도 자동으로 메모리가 반환되지 않습니다.
그러므로 free해줘야하며, free 해주지 않을경우 지속적으로 heap공간을 차지하고 함수의 반복호출시 계속 heap에 누적되어 메모리 누수를 발생시킵니다.
피드백을 보고나서 메모리 할당 해제하는 부분을 추가해보았다.
// 두 문자열이 애나그램인지 확인해주는 함수
int is_anagram(const char* s1, const char* s2) {
// 두 문자열의 길이 비교
if(strlen(s1) != strlen(s2)) {
printf("두 숫자의 길이가 다릅니다. \n");
return 0;
}
// 선택 정렬을 통해 정렬된 문자열 저장
char* sorted_s1 = selection_sort(s1);
char* sorted_s2 = selection_sort(s2);
// strcmp() 함수로 정렬된 두 문자열을 비교해서 같은지 확인
if (strcmp(sorted_s1, sorted_s2) == 0) {
// malloc() 로 할당해준 메모리 해제
free(sorted_s1);
free(sorted_s2);
// if() 조건문 안에서 1 이면 True 를 의미하기 때문에 같으면 1 을 반환
return 1;
} else {
// malloc() 로 할당해준 메모리 해제
free(sorted_s1);
free(sorted_s2);
// if() 조건문 안에서 0 이면 False 를 의미하기 때문에 같으면 0 을 반환
return 0;
}
}selection_sort() 함수에서 메모리를 할당 받아 포인터를 통해 sorted_s1, sorted_s2 에 넣어주었고
is_anagram() 함수에서 사용한 후 free() 를 통해 메모리 할당을 해제해주었다.
📌 문제 2
이 문제를 해결하기 위한 핵심은 각 위치의 중앙값과 평균값을 구해서 두 개의 값을 통해 주어진 집까지의 거리의 합을 구해준 뒤 더 작은 값을 출력하면 되는 문제였다. 계산한 순서를 살펴보면 다음과 같다.
1. 중앙값과 평균값을 구한다.
2. 각각의 값을 통해 집마다의 거리의 합을 구한다.
3. 중앙값을 통해 얻은 거리의 합과 평균값을 통해 얻은 거리의 합을 비교한다.
4. 거리의 합이 더 작은 값이 친구들과 최단거리에 있는 집의 위치가 된다.
우선 함수화 하는데 중점을 두어 코드를 작성해보았다.
굳이 함수를 사용하지 않아도 되지 않나? 라는 생각을 했지만 한 번에 여러 개의 입력값을 받기 위해서 함수화를 통해 코드를 작성했다.
#include <stdio.h>
#include <stdlib.h>
#include <cs50.h>
// 함수 선언
void print_result(int length, int locations[]);
int get_center_value(int length, int locations[]);
int get_average_value(int lnegth, int locations[]);
int sum_distance(int length, int locations[], int value);
int* bubble_sort(int length, int locations[]);
int main(int argc, char* argv[]) {
// 입력값 배열 선언
int location1[4] = { 2, 2, 2, 4 };
int location2[5] = { 1, 2, 3, 4, 5 };
int location3[4] = { 5, 3, 5, 6 };
// 결과 출력
print_result(sizeof(location1)/sizeof(int), location1);
print_result(sizeof(location2)/sizeof(int), location2);
print_result(sizeof(location3)/sizeof(int), location3);
}
// 결과 출력 함수
void print_result(int length, int locations[]) {
int center_val = 0;
int average_val = 0;
int result;
printf("입력값: ");
for (int i=0; i<length; i++) {
printf("%d", locations[i]);
}
center_val = get_center_value(length, locations); // 중앙값
average_val = get_average_value(length, locations); // 평균값
int sum_for_center = sum_distance(length, locations, center_val); // 중앙값을 통해 구한 거리의 합
int sum_for_avg = sum_distance(length, locations, average_val); // 평균값을 통해 구한 거리의 합
result = (sum_for_center >= sum_for_avg) ? average_val : center_val ;
printf(" -> 출력값: %d\n", result);
}
// 중앙값을 구하는 함수
int get_center_value(int length, int locations[]) {
int center = 0; // 중앙 위치
int center_val = 0; // 중앙 값
// 중앙 값을 구하기 위해 버블 정렬을 해준다.
int* sorted_location = bubble_sort(length, locations);
// 중앙 위치 구하기
if(length % 2 == 0) { // 배열의 길이가 홀수의 경우
center = length/2 - 1;
} else { // 배열의 길이가 홀수의 경우
center = length/2;
}
center_val = sorted_location[center]; // 중앙 위치를 구해 배열의 중앙값을 구한다.
return center_val;
}
// 평균값을 구하는 함수
int get_average_value(int length, int locations[]) {
int avg_val = 0;
// 평균값 구하기
for (int i=0; i<length; i++) {
avg_val += locations[i]; // 모든 배열의 값을 더해준다.
}
avg_val = avg_val / length; // 다 더해준 값을 배열의 개수로 나누어준다.
return avg_val;
}
// 거리의 합을 구하는 함수
int sum_distance(int length, int locations[], int value) {
int sum = 0;
for (int i=0; i<length; i++) {
if(locations[i] < value) { // 값보다 작을 경우
sum += (value - locations[i]);
} else { // 값보다 클 경우
sum += (locations[i] - value);
}
}
return sum;
}
// 버블 정렬 함수
int* bubble_sort(int length, int locations[]) {
int temp;
for (int i=0; i<length; i++) {
for (int j=0; j<length-i-1; j++) {
if(locations[j] > locations[j+1]) {
temp = locations[j];
locations[j] = locations[j+1];
locations[j+1] = temp;
}
}
}
return locations;
}
[실행 결과]

추가적으로, 굳이 함수화해서 코드를 길게 늘릴 필요가 있나? 에 대해서 더 고민해봐야겠다. 물론 단발성인 결과를 얻고 싶다면 굳이 함수를 사용해서 코드를 작성하지 않아도 될 것 같다. 하지만 여러 개의 값을 받아 여러 번 사용해야 한다면 중복되는 부분들을 함수화를 통해 분리해준다면 가독성이 좋은 그리고 효율적인 코드를 작성할 수 있지 않을까 생각한다.
'스터디&교육 > 부스트코스 CS50 2기' 카테고리의 다른 글
| 부스트코스(Boostcourse) CS50 5주차 심화 과정 💎 생각해보기(2) (0) | 2021.02.19 |
|---|---|
| 부스트코스(Boostcourse) CS50 5주차 심화 과정 💎 생각해보기(1) (0) | 2021.02.19 |
| 부스트코스(Boostcourse) CS50 3주차 심화 과정 💎 생각해보기 (0) | 2021.01.23 |
| 부스트코스(Boostcourse) CS50 2주차 심화 과정 💎 생각해보기 (0) | 2021.01.19 |
| 부스트코스(Boostcourse) CS50 2주차 C언어 - 문자열 (1) | 2021.01.15 |